Un code a les preuves du temps

Au travers de l’article Démarche de portage d’un “legacy” Ada nous avions présenté les principaux problèmes pouvant être rencontrés lors d’un portage d’un legacy Ada et la façon de les adresser au mieux. L’approche ainsi proposée était « classique » et elle ne faisait aucunement appel aux méthodes formelles au travers par exemple de la technologie SPARK.
Dans le présent article, nous allons vous présenter en quoi la technologie SPARK peut conforter cette approche « classique ».
Rappels sur la technologie SPARK¶
SPARK est un sous-ensemble (subset) du langage Ada2012 permettant d’aborder le développement d’applications critiques. Comme Ada2012, SPARK formalise les propriétés d’une opération (par exemple sa sémantique), les propriétés pouvant être vérifiées de façon statique (prouveur) et/ou dynamique (run-time).
SPARK au travers d’une approche formelle va vérifier que :
Le flot de données d’un programme est en accord avec les informations fournies.
La sémantique des opérations est en accord avec celle disponible ou exprimée.
Le code ne lèvera pas d’exceptions (AoRTE : Absence of RunTime Errors).
SPARK s’appuie sur des propriétés exprimées au travers :
D’un subset de la syntaxe et de la sémantique du langage Ada.
D’une syntaxe et d’une sémantique propre à SPARK.
L’expression de la sémantique (propriété), peut se faire soit par le biais de contrats sur des types, soit par le biais de contrats sur des opérations :
-- exemple de contrat sur un type: type Polyedre T is tagged record F, -- Son nombre de faces. A, -- Son nombre d'arêtes. S : Natural; -- Son nombre de sommets. end record -- Théorème d'Euler (invariant topologique). with Type Invariant => Polyedre T.S - Polyedre T.A + Polyedre T.F = 2; -- exemple de contrat sur une opération: procedure Sort (Vector : in out Vector T) is -- Sort produit un vecteur trié par odre croissant. with Post => (for all I in Vector'Range => I = Vector'Last or else Vector(I) <= Vector(I+1) );
SPARK, ce sont aussi des niveaux d’adoption :
Stone Level : Le code respecte le subset Ada → on s’affranchit d’erreurs de base tout en respectant un standard.
Bronze Level : Le flot de données est vérifié → plus de variables non initialisées, plus de problèmes d’aliasing, plus d’affectations inutiles, plus de variables non utilisées, etc.
Silver Level : Absence d’exceptions (implicites ou explicites) (AoRTE).
Gold Level : Respect des propriétés du programme → respect des contrats sur les opérations et les types.
Pour terminer, une caractéristique de SPARK est aussi son aptitude à pouvoir combiner la preuve formelle avec d’autres méthodes de vérification plus « classiques ».
Pourquoi utiliser la technologie SPARK dans le cadre d’un portage¶
On peut raisonnablement considérer qu’un code legacy est bon d’un point de vue fonctionnel (proven in use) mais cela ne garantit en rien que le code concerné soit correct. Par exemple, une variable non initialisée aura peut-être la « bonne » valeur dans son contexte legacy mais rien ne garantit que cela sera toujours le cas après portage. De toute manière, il n’est pas acceptable qu’un code erroné soit reconduit à l’issue du portage.
Même si l’ensemble des préconisations faites dans 4 (adhérences à l’implémentation du compilateur source et/ou permissivité du compilateur source) doivent permettre de détecter ce type de problème, l’exhaustivité n’est cependant pas garantie et la mise en œuvre de la technologie SPARK permet de conforter cette démarche d’assainissement du code.
Nous allons ici nous focaliser sur le Bronze Level et dans une moindre mesure sur le Silver Level.
La mise en œuvre de SPARK nécessite que le code concerné respecte le subset Ada requis par le Stone Level.
Le Stone Level implique donc un certain nombre de restrictions qui sont :
Pas d’effet de bord dans une expression,
Pas d’aliasing de noms,
Limitations dans l’usage des pointeurs,
Pas de types contrôlés,
Pas de handlers d’exceptions,
Tasking Ada restreint au profile d’exécution Jorvik.
Le code legacy ne répondant probablement pas aux exigences du Stone Level, une « SPARKification » de ce dernier sera nécessaire. Cette « SPARKification » peut se traduire par un refactoring pouvant être gardé à terme, car il contribuera à améliorer le code.
Cela étant, cette « SPARKification » peut représenter un effort conséquent. C’est entre autres pour cela que l’outil ASAP (Ada-SPARK Assisted Porting) a été développé par Systerel.
L’outil ASAP¶
Pourquoi l’outil ASAP ?¶
Les efforts de « SPARKification » se sont rapidement révélés être très répétitifs, et donc propices à l’assistance par un outil. Cependant, les contraintes de SPARK restent d’assez haut niveau, ce qui laisse peu de place à l’automatisation.
L’outil développé est donc une assistance manuelle, qui permet des transformations du code guidées par une analyse humaine. Il y a alors un constant aller-retour entre l’outil et l’utilisateur.
Par exemple, l’identification des fonctions qui ont des effets de bord est une tâche difficile, et la décision de déplacer les effets de bord ou de transformer la fonction en procédure se prend au cas par cas et ne peut pas être automatisée. Une fois que la transformation de fonction en procédure a été décidée, le remplacement de tous les appels est fait efficacement par l’outil ASAP.
Architecture et technologie¶
Comme il s’agit avant tout d’un outil d’analyse et de modification du code Ada, il doit se baser sur une bibliothèque d’analyse lexicale et syntaxique d’Ada. Il en existe deux principales : ASIS et libadalang. Nous avons opté pour l’utilisation de la librairie libadalang dans sa déclinaison Ada car celle-ci est jugée plus pérenne.
Le langage Ada n’étant pas le plus adapté pour manipuler les fichiers texte que sont les codes sources, il a été décidé de scinder l’outil en deux parties.
La partie Ada dédiée à l’analyse et la partie Python dédiée à la manipulation des codes sources.
Le schéma ci-dessous, représente l’architecture globale de l’outil ASAP :
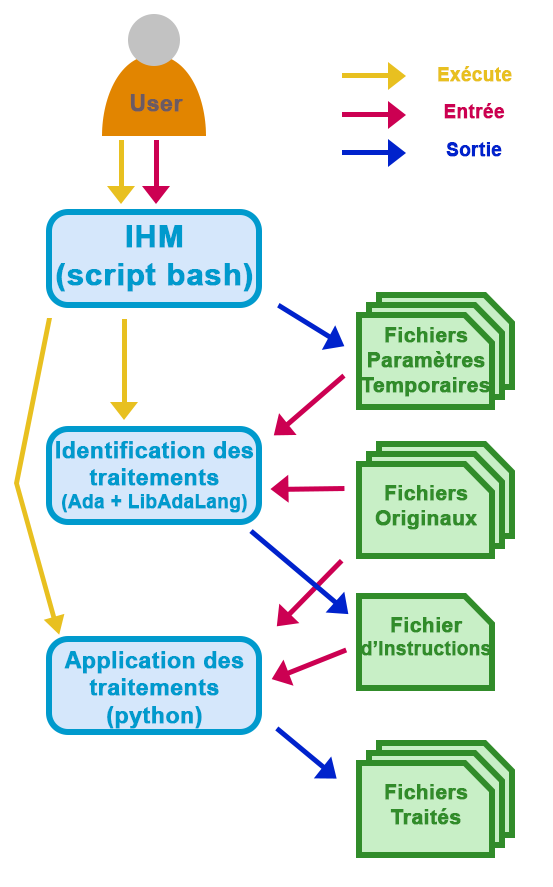
Architecture globale de l’outil ASAP
Mise en œuvre d’ASAP¶
L’outil est complètement piloté par une interface utilisateur basée sur des menus, comme on peut le voir sur la capture d’écran ci-dessous :
Selectionnez le traitement souhaité : @ - cancel and exit 1 - ajouter "SPARK Mode => On” aux packages ne l'ayant pas ---STONE--- 2 - fonction avec effet de bord 3 - initialisation dépendante d'une variable 4 - commenter les exceptions utilisant "raise” ---BRONZE--- 5 - ajouter "Relaxed Initialization™ sur les variables non scalaires ---SILVER--- 6 - propager les préconditions d'une variable traitement de fonction a effet de bord renseignez le nom de la fonction à transformer en procedure INIT add another function ? (y/n) y renseignez le nom de la fonction à transformer en procedure FUNC add another function ? (y/n) n
Exemple de ce que sait faire ASAP¶
Les cas typiques d’utilisation d’ASAP sont les transformations répétitives sur des structures de code faciles à identifier :
transformer des appels de fonction à effet de bord en appels de procédure, en ajoutant une variable intermédiaire ;
supprimer les traite-exception qui se terminent par une instruction raise. Ce sont généralement des traces ou de la libération de ressources qui n’ont pas lieu d’être dans le paradigme sans exception de SPARK ;
propager des préconditions sur des paramètres de sous-programme vers les sous-programmes appelants qui ont ces mêmes paramètres en entrée.
…
Limitations actuelles et évolutions prévues d’ASAP¶
Certaines limitations d’ASAP sont liées à la complexité conceptuelle de SPARK, obligeant à rester un minimum dans une logique d’assistance à l’action humaine.
En revanche, il est toujours possible d’ajouter de nouveaux types de transformation de code. Ici, la limite est l’équilibre entre le temps passé à développer une nouvelle transformation et le temps gagné en l’utilisant.
L’expérience montre que les niveaux les plus bas sont plus propices aux modifications semi-automatiques, et nous nous attendons à ce que cet outil reste beaucoup plus utile pour atteindre le niveau stone que pour progresser dans les niveaux supérieurs.
D’autre part, la fréquence des allers-retours entre ASAP et le code rend l’interface utilisateur très importante pour cet outil. C’est sur ce point que l’outil va être amélioré : une intégration de l’outil ASAP à GNAT studio au travers d’un greffon est envisagée.
Retour d’expérience et conclusions¶
L’approche formelle en tant que telle sur du code legacy peut être vue comme difficile voire impossible. La souplesse de SPARK permet de se limiter à une fraction de ses capacités en se cantonnant aux premiers niveaux tout en bénéficiant largement de la pertinence de l’approche. Par exemple, le niveau bronze permet de s’assurer de la bonne initialisation de toutes les données, pour un coût compétitif en regard de l’analyse manuelle.
Le niveau stone est un prérequis pour toutes les analyses SPARK et l’outil ASAP permet de minimiser de façon significative l’effort nécessaire pour satisfaire ce prérequis.
Les principaux freins à la « SPARKification » sont l’abus de type access, le tasking Ada sans les contraintes Ravenscar ou Jorvik, et une utilisation maladroite des exceptions. Ces cas peuvent être isolés et exclus facilement de l’analyse SPARK. Le reste du code peut alors bénéficier des atouts de cette technologie.
Ainsi donc, à l’issue du portage, notre code sera à l’épreuve du temps !