Traitement de données BIM pour la validation
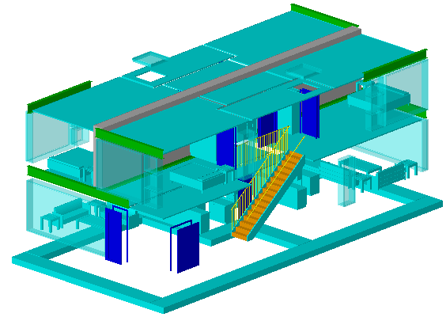
Le domaine ferroviaire est en train de s’ajouter à la liste des domaines qui peuvent utiliser la méthodologie BIM. Cette dernière étant en plein gain de popularité, il est probable que cela ait un impact sur l’industrie ferroviaire dans son ensemble. En particulier, qu’en est-il pour nos activités de validation de données ? Quelles similarités avec nos procédés actuels, y a-t-il des changements à effectuer, à quel niveau ? C’est ce que je propose d’étudier dans l’article suivant sur les perspectives d’utilisation du BIM dans un cadre formel pour la validation.
Cet article présente le contexte et les résultats du stage d’Aixandre Hubert.
Contexte¶
Le BIM (Building Information Modeling) est une méthodologie standardisée pour la réalisation de projets de construction, centrée sur l’interopérabilité et la communication. Un format de données poussé par ce standard est le .ifc (Industry Foundation Classes) qui, dans sa version en cours d’écriture (la 4.3.x), va venir apporter le support pour la description d’infrastructures ferroviaires. Le standard est de plus en plus utilisé et est même poussé par certains pouvoirs publics (par exemple dans le code de constructions publiques en Italie).
Avant même que le ferroviaire n’intervienne, des industriels du secteur expérimentaient avec le BIM sur des bâtiments « classiques ». Les nouvelles possibilités offertes par le .ifc permettent alors de compléter la modélisation de leurs infrastructures. Comme Systerel effectue déjà de la validation de données pour ces entreprises, il convient de s’intéresser à ce format de données pour se préparer, le cas échéant, aux nouvelles demandes.
Objectif¶
Ce qui nous intéresse principalement dans le BIM, c’est l’aspect maquettage des constructions. Les maquettes BIM contiennent plusieurs informations : la description géométrique et physique, les matériaux en jeu, les délais, les coûts, et même les procédés de réalisation à utiliser. Ce sont ces maquettes que l’on va étudier, et dont on va essayer de valider les données (en vérifiant des propriétés dessus).
On se basera sur l’outil OVADO²® pour les travaux, qui sert à vérifier (et générer) des données de configuration1. Un des deux formats (avec le Excel) pour les données d’entrées du logiciel est le XML, c’est sur celui-ci qu’on va se baser. L’objectif principal est donc de traduire (fidèlement et sans perte de sémantique) des données IFC en données XML, afin de pouvoir utiliser la validation des données traduites pour déduire les résultats sur les maquettes BIM.
Les IFC¶
C’est le format de données utilisé pour exprimer les maquettes BIM, pensé pour les logiciels de conception/fabrication assistée par ordinateur. Les fichiers du format se présentent comme une suite de déclarations, ligne par ligne, d’entités IFC. Ces entités sont issues de la documentation IFC (pour la version 4.3.x) et suivent toutes le même format :
#identifiant=type_de_l'entite(valeur_attribut_1,valeur_attribut_2,...,valeur_attribut_N)
Les valeurs des attributs sont une parmi :
- nombre réel,
- chaine de ca,ractères
- absence de valeur, symbolisée par un
$, - autre entité IFC (déjà déclarée ou non),
- liste d’entités IFC.
L’image suivante présente un extrait de quatre lignes d’un fichier IFC pour montrer à quoi ressemblent les entités auxquelles on est confrontés.
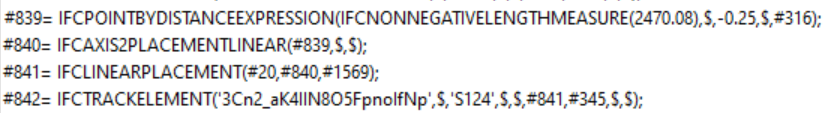
Cela donne quelques exemples d’entités et des valeurs pour leurs attributs. Ce que l’on peut constater, c’est que le « type » des attributs n’est pas explicité, il faut se référer à la documentation pour le connaître. Un aspect intéressant qui est aussi illustré, c’est le principe de « chaînes » d’entités. En effet, on peut voir que l’entité #842 référence, dans l’un de ses attributs, l’entité #841, qui elle-même pointe sur #840 puis #839, etc.
C’est un schéma typique des IFC : un objet réellement physique (par exemple un cube) va habituellement être déclaré en plusieurs lignes, allant du « haut niveau » (un repère relatif pour le placement, l’appartenance à un groupe…) au « bas niveau » (déclaration des points 3D qui composent les arêtes). Dans l’exemple, l’élément de voie (ici une traverse, typée par une autre entité du fichier) est déclaré en #842. En #841 et #840 est déclaré le repère relatif par rapport auquel l’élément est placé, et en #839 le placement dans ce repère (ici une distance par rapport à l’origine de la voie).
Récupération des informations¶
L’idée est d’exploiter les chaînes de déclarations pour obtenir les informations relatives à un objet. Les IFC font un bon travail pour décrire de manière simple les objets, même si des fois certains aspects demandent explicitation. L’objectif final est de produire un fichier XML avec toutes les informations/grandeurs nécessaires pour vérifier un ensemble de propriétés. C’est à nous d’identifier ces informations dans les fichiers IFC, et de les transcrire dans ce que l’on appellera des « attributs XML ».
Pour certaines propriétés, les attributs sont exprimés en clair dans le fichier et ne nécessitent aucune manipulation. C’est le cas par exemple pour une propriété du style « les traverses adjacentes sur la voie sont à une distance comprise entre 40 et 70 centimètres ». Pour vérifier cela, il suffit d’avoir un identifiant unique pour les éléments et la distance en question, qui sont, du point de vue conceptuel des IFC, des grandeurs « basiques » d’un élément de voie. Tous ces attributs sont explicités dans le fichier et la récupération d’informations consiste simplement à extraire ces valeurs, comme on peut le voir dans l’image suivante.
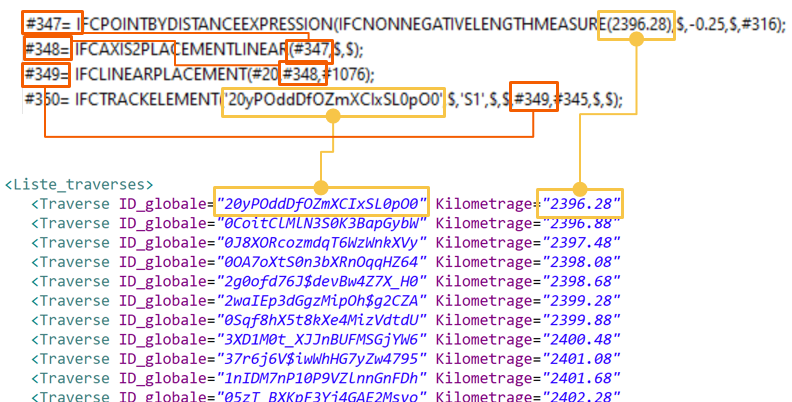
On a ici l’exploitation de la chaîne #350 → #349 → #348 → #347 pour récupérer les deux informations et les copier dans un fichier XML. Une fois que l’ensemble du fichier IFC a été traité, on se retrouve avec un fichier XML à partir duquel on peut effectuer de la validation de données classique depuis OVADO²®.
Si tout était explicité comme ici, on n’aurait aucun problème à utiliser le .ifc en l’état puisqu’il s’agit de piocher au bon endroit. Cependant, certaines informations plus « complexes » nécessitent des calculs depuis les grandeurs brutes et forcent un traitement plus fin de l’information.
Calculs intermédiaires¶
Prenons une propriété qui s’intéresse aux croisements entre des voies. Logiquement, il nous faudrait des attributs XML qui représentent les croisements, les voies en jeu, la position, etc. Malheureusement (pour nous), il est tout à fait possible qu’il n’y ait aucune entité IFC qui représente cette information. En effet, elle n’est pas nécessaire pour caractériser des voies, c’est « implicite » et calculable à partir des grandeurs basiques.
Conceptuellement (pour les IFC), une voie est constituée de trois profils : horizontal en vue de dessus, vertical en vue de côté et longitudinal en vue en long. Chaque profil est constitué de segments (tronçons avec une unique forme géométrique), qui ont leur propre type d’entité IFC. Ces entités permettent le paramétrage des segments grâces à leurs différents attributs. L’image suivante montre les paramètres (et les unités) pour un segment du profil horizontal :

… et c’est tout. On n’a que ça pour situer et représenter un segment horizontal. Pas de point de fin, pas de positionnement relatif à un autre segment, pas d’information explicite par rapport au reste des voies. Les seules autres informations sont les segments qui composent le même profil et leur ordre sur la voie. Ainsi, on doit calculer à la main les croisements en étudiant la proximité entre les différents segments.
Sans rentrer trop dans les détails, il est tout à fait possible d’effectuer ces calculs et d’aboutir à des résultats corrects. Cet exemple a plus pour but de montrer qu’il existe des propriétés qui sont vérifiables sur les données, mais qui nécessitent des calculs supplémentaires avant l’étape de validation. De plus, il est à noter que l’entité IFC pour représenter un croisement (physiquement l’élément de voie associé) existe, mais qu’il n’y a aucune obligation pour son utilisation. Il existe des façons de spécifier/d’exiger l’agencement et les informations pour des fichiers IFC, mais les solutions proposées sont, elles aussi, globalement en cours de développement.
Limitations¶
Cet aspect calculatoire en soi n’est pas un problème, mais il fait apparaître quelques limitations dans le cadre des travaux. Une manière intéressante de procéder serait d’abord d’extraire les données brutes d’un fichier IFC, et d’importer le tout dans OVADO²® (voire d’importer le fichier .ifc en lui-même). Le logiciel pourrait ensuite procéder aux calculs intermédiaires et effectuer la validation de données subséquente. Cela garantirait l’intégrité des données sur la traduction et permettrait d’utiliser les qualifications d’OVADO²® pour certifier les processus. Cependant, le logiciel n’est pas adapté pour ce genre de considérations, ce qui fait que les calculs intermédiaires doivent être réalisés par d’autres moyens (en l’occurrence, en Python). Une perspective d’amélioration pour OVADO²® dans le cadre de projets BIM serait donc de réfléchir au support pour des calculs de géométrie et de représentation.
Une autre difficulté intervient lors du passage à l’échelle, puisque nous avons travaillé sur des fichiers « jouets », assez légers. Pour comparer, la plupart des fichiers en 4.3.x traités ne sont de l’ordre que de quelques milliers de lignes. Nous avons aussi étudié un fichier d’une version précédente (2x3, standardisée) et celui-ci faisait presque un million de lignes. La masse des données à manipuler n’est pas la même, et cela se peut se ressentir justement quand il faut effectuer des calculs, qui peuvent prendre beaucoup plus de temps. Il est donc important d’optimiser les calculs pour éviter de perdre trop de temps là-dessus. Par exemple, pour ce qui est relatif à la recherche spatiale et après consultation interne, nous avons opté pour l’utilisation de R-trees (une structure arborescente spécialisée), mais cette réflexion peut/doit être faite pour tous les calculs intermédiaires. Sur des fichiers de 6 000 lignes, les calculs (sans optimisation) peuvent prendre plus de deux minutes, ce qui n’est pas excessif, mais qui montre tout de même qu’il est important de faire cet effort sur des données bien plus volumineuses.
Conclusions et perspectives¶
Il apparait que la validation de données BIM (via le format IFC) dans OVADO²® est possible et ne présente aucun aspect réellement bloquant.
Cela étant dit, il faut garder à l’esprit qu’il s’agit de travaux expérimentaux qui ne reflètent aucunement l’ampleur d’un véritable projet, que ce soit en termes de validation côté OVADO²® ou de construction côté BIM. Une première perspective évidente serait donc de s’intéresser à un tel projet pour renforcer nos conjectures (ou non).
La question de la façon dont sont faits les calculs intermédiaires est aussi une piste à creuser, pour dépendre le moins possible d’outils non qualifiés qui affaibliraient la crédibilité de la validation de données associée. L’idéal serait de pouvoir tout faire depuis OVADO²®, mais cela nécessiterait un développement supplémentaire à contrebalancer avec le potentiel d’une validation de données BIM pour les industriels du domaine de l’infrastructure ferroviaire.
Enfin, il serait pertinent de regarder d’un peu plus près les moyens de spécifications sur les fichiers IFC. Cela pourrait permettre de réduire, voire d’éliminer, le besoin de calculs intermédiaires. En effet, une connaissance (ou même un catalogue) des propriétés à vérifier permettrait d’exiger en amont certaines grandeurs et attributs. Sachant que les entités IFC disponibles permettent la plupart du temps d’exprimer des objets que l’on va être amenés à vérifier (la nouvelle version a été pensée et conceptualisée par les industriels et les experts du secteur), le gain de temps serait conséquent.
Maintenant, il faut attendre que la version IFC 4.3.x soit standardisée pour voir si son utilisation dans l’industrie justifie les aménagements développés ci-dessus. En tout cas, il nous semble tout à fait possible de commencer à réfléchir à une transition dans le futur si besoin est.