Intégration continue à Systerel
Cet article a pour objectif d’expliciter la notion d’intégration continue et de montrer comment tout un chacun peut la mettre en œuvre sur son projet à Systerel.
Qu’est-ce que c’est ?¶
Selon Wikipedia :
L’intégration continue (aussi appelée CI) est un ensemble de pratiques utilisées en génie logiciel consistant à vérifier à chaque modification de code source que le résultat des modifications ne produit pas de régression dans l’application développée.
L’objectif de cette pratique est :
de détecter les problèmes au plus tôt lors du développement, idéalement à chaque push,
-
d’avoir en permanence une branche principale pour laquelle tous les tests passent (seulement si on développe sur des branches autres que master). Ce qui permet :
de pouvoir livrer rapidement un logiciel fonctionnel,
à chacun des développeurs de démarrer des travaux en partant d’une branche master saine.
En pratique à chaque fois qu’une tâche de vérification est automatisable, on gagnera à la faire en intégration continue. De même, si un défaut est identifié sur une livraison, il est intéressant lorsque cela est possible d’ajouter à l’intégration continue une vérification permettant de contrer ce défaut.
Comment ça marche ?¶
En pratique, Systerel met à disposition un serveur gitlab en interne, accessible à l’adresse https://gitlab.aix.systerel.fr. Vous pouvez vous y connecter en utilisant le bouton Sign in with Systerel, puis vos identifants de l’ERP :
Ensuite vous créez un projet sur le gitlab (dont le dépôt peut être hébergé par le gitlab ou bien un miroir d’un dépôt sur PCB 1) et mettez en place un fichier de configuration de l’intégration continue (voir ci-après).
Enfin, sur chaque push, gitlab va lancer les jobs décrits dans le fichier de configuration sur l’un des runners 2 disponibles (c’est-à-dire configuré et non occupé), en parallélisant autant que possible et vous informer si les tâches ont échoué.
Exemples¶
S2OPC¶
Vous pouvez consulter les intégrations continues mises en place pour des projets open-source. Voici par exemple le pipeline de S2OPC :
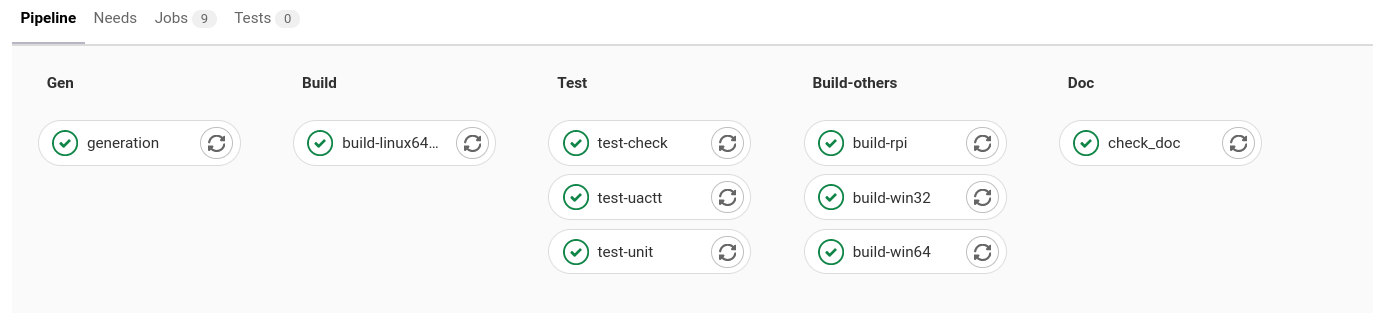
Affichage du pipeline de S2OPC
On y trouve les différentes phases (stage dans la terminologie gitlab) définies par le projet :
Genpour la génération de code C à partir du modèle BBuildpour la compilation sous linuxTestpour le déroulement des différents types de testsBuild-otherspour la compilation sur d’autres ciblesDocpour la vérification de la documentation
Si l’une des tâches échoue, le pipeline est signalé en erreur et un mail est envoyé à la personne qui a réalisé le push qui a donné lieu à cette itération d’intégration continue.
Projet interne — dataprep L6¶
Le projet C845 de génération et validation de données pour la Ligne 6 du métro a une CI un peu plus compliquée qui met en place des dépendances entre tâches, ce qui permet de paralléliser un maximum le déroulement des vérifications.
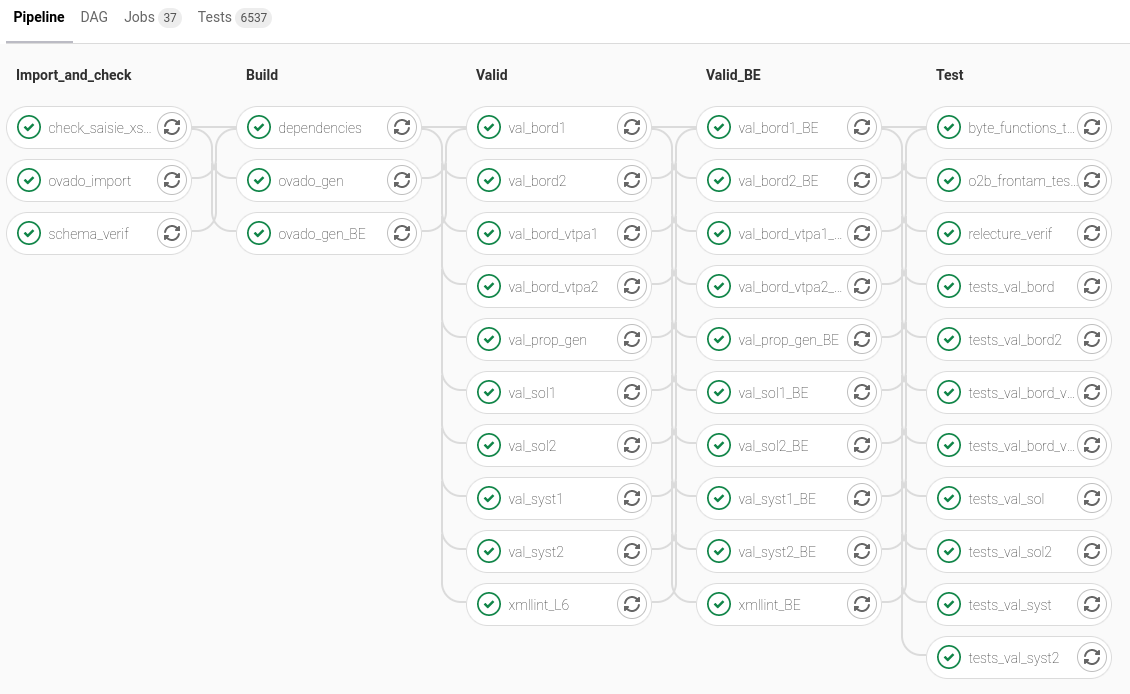
Affichage du pipeline du projet C845
On y voit notamment qu’il y a deux étapes de validation correspondant aux deux lignes (L6 et Base d’Essais), et que ces étapes sont constituées d’une série de tâches de validation sur des parties différentes du système (bord, sol, …).
La dernière étape de Test comprend des tâches de :
test logiciel des outils spécifiques au projet,
test en erreur des propriétés du modèle,
vérification de la cohérence des fiches de relecture et du modèle.
Mise en place¶
Il existe différents systèmes pour définir les tâches et leur enchaînement, ainsi que l’environnement dans lesquelles elles seront exécutées. De manière générale, un fichier de configuration géré en configuration dans l’espace projet (sous git) est utilisé pour décrire tout cela de manière statique.
La documentation est en général disponible en ligne :
À Systerel, nous utilisons deux systèmes d’intégration continue. L’ancien Jenkins qui n’a plus vocation à être utilisé sur de nouveaux projets et l’instance locale de gitlab.
Dans la suite nous allons vous montrer comment mettre en place une intégration continue sur votre projet.
Création du projet gitlab¶
Si vous êtes chef de projet ou responsable de département, vous pouvez créer
un projet sous le groupe cNNN correspondant au numéro de contrat en
vous rendant sur https://gitlab.aix.systerel.fr/cNNN et en cliquant sur
le bouton : 
Si vous voulez juste essayer sans polluer un espace projet, vous pouvez
toujours créer un projet personnel en utilisant le même bouton sur la
page d’accueil. Sachez seulement
qu’à la différence des projets créés dans les groupes cNNN, ceux-ci
ne sont pas sauvegardés par le SI.
Notez que pour pouvoir faire un push vers gitlab, il vous faudra
ajouter votre clef publique ssh dans votre compte :
https://gitlab.aix.systerel.fr/profile/keys
Création du .gitlab-ci.yml
¶
Tout d’abord, clonez votre dépôt en local (en supposant que ce dernier
ait pour nom test_ci et en remplaçant USERNAME par votre login
gitlab) :
git clone "ssh://git@gitlab.aix.systerel.fr:2224/USERNAME/test_ci"
Et ajoutez en configuration le fichier .gitlab-ci.yml ci-après qui décrit
un pipeline d’intégration continue (c’est-à-dire l’ensemble des actions qui
devront être lancées) permettant de simuler une compilation (stage: build,
deux tâches de test (stage: test) et une tâche de déploiement (stage:
deploy).
Sans information de dépendances supplémentaires entre tâches, les phases (stage) sont séquencées dans l’ordre et le pipeline s’arrête dès qu’une
des phases n’a pas toutes ses tâches (job) qui ont réussi.
build-job: stage: build script: - echo "Hello, $GITLAB_USER_LOGIN!" test-job1: stage: test script: - echo "This job tests something" test-job2: stage: test script: - echo "This job tests something, but takes more time than test-job1." - echo "After the echo commands complete, it runs the sleep command for 20 seconds" - echo "which simulates a test that runs 20 seconds longer than test-job1" - sleep 20 deploy-prod: stage: deploy script: - echo "This job deploys something from the $CI_COMMIT_BRANCH branch."
avec les commandes :
git add .gitlab-ci.yml git commit -m "Add initial CI configuration"
Enfin, poussez le tout vers le gitlab pour déclencher les travaux d’intégration continue.
git push -u origin master # pousse sur gitlab et associe la branche locale master à la branche distante de même nom
Vous pouvez alors constater sur https://gitlab.aix.systerel.fr/USERNAME/test_ci/-/pipelines que les différentes tâches d’intégration continue se sont bien exécutées :
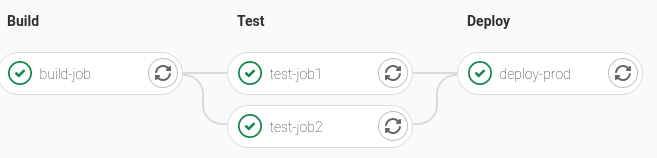
Affichage du pipeline
Réutilisation des résultats¶
Il est souvent nécessaire de réutiliser les résultats d’une tâche précédente. Par exemple pour dérouler les tests, on utilise l’exécutable produit pendant la phase de compilation. Gitlab utilise pour cela la notion d’artefacts.
Modifiez votre fichier .gitlab-cy.yml comme suit pour ajouter un
artefact en phase de build et l’utiliser dans les tests :
@@ -1,12 +1,17 @@ build-job: stage: build script: - - echo "Hello, $GITLAB_USER_LOGIN!" + - echo "Hello, $GITLAB_USER_LOGIN!" | tee "result.txt" + artifacts: + paths: + - result.txt + expire_in: 1 day test-job1: stage: test script: - echo "This job tests something" + - grep "Hello" result.txt test-job2: stage: test @@ -15,6 +20,7 @@ test-job2: - echo "After the echo commands complete, it runs the sleep command for 20 seconds" - echo "which simulates a test that runs 20 seconds longer than test-job1" - sleep 20 + - grep "Jonathan Livingston" result.txt deploy-prod: stage: deploy
La CI s’exécute et donne le résultat attendu suivant :
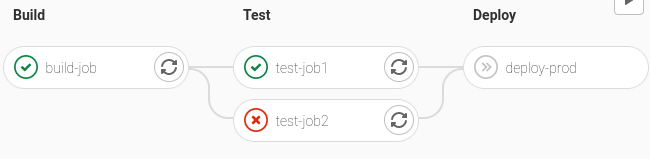
Affichage du pipeline modifié
On peut voir que le grep de test-job1 a réussi, mais que celui de
test-job2 a échoué comme attendu et que la dernière tâche n’a pas
été exécutée, car elle dépend de la bonne exécution de l’étape (stage) précédente.
Le fichier result.txt est consultable sur l’interface du gitlab dans
la liste des artefacts associés à la tâche build-job.
Bonnes pratiques¶
Avoir une CI rapide¶
L’idée d’une intégration continue est de permettre au développeur d’avoir un retour rapide sur ses modifications. Il est donc important :
de commiter et pousser souvent sa branche de développement,
de minimiser le temps d’exécution de la CI.
Dans le cas contraire, cela oblige le développeur à changer de contexte pour prendre en compte le résultat de la CI, ce qui est parfois compliqué.
On peut être amené à découper les tâches de la CI en différents groupes. Un premier qui est exécuté à chaque push et un second (par exemple pour des tests de performance qui peuvent être long à exécuter) qui seront exécutés toutes les nuits.
Travailler sur des branches¶
L’idéal est d’avoir en permanence un master pour lequel l’intégration continue est au vert. Chaque développeur qui démarre une branche pour développer une fonctionnalité sait alors qu’il part sur des bonnes bases et qu’il a la responsabilité de livrer une branche qui garde la CI au vert (par défaut, la CI est lancée sur toutes les branches qui sont poussées sur le gitlab).
Utiliser une image docker¶
Il est courant d’avoir besoin d’un environnement spécifique pour
exécuter les tests (un compilateur spécifique, un environnement de
développement python avec des paquets préinstallés, …). Pour cela on
utilisera une image docker dont l’adresse est spécifiée par le champ
image: (global ou spécifique à un job). Par exemple :
doc: image: "docker.aix.systerel.fr/c462/sysdoc:0.1" script: - make
Les images peuvent provenir :
de dépôts publics comme Docker Hub,
du dépôt interne de Systerel : https://docker.aix.systerel.fr/,
d’une image fabriquée sur votre machine, voire par l’intégration continue et mise à disposition dans le registre d’image docker de votre projet : https://gitlab.aix.systerel.fr/USERNAME/test_ci/container_registry (nous avons des exemples de fabrication dans un job de l’intégration continue. N’hésitez pas à demander à la DT si vous avez ce genre de besoin).
Utiliser des services¶
La CI permet de réaliser des tests unitaires, mais aussi des tests d’intégration ou des tests fonctionnels. Par exemple, pour tester un serveur web, nous avons peut-être besoin d’avoir une base de données opérationnelle (postgres, mongodb, redis ou autre). Il est possible dans ce cas de définir un service associé au job au moyen d’une image docker. Concrètement, l’image sera démarrée avant l’exécution du job et le service inclus dans l’image sera disponible via le réseau.
Le job suivant définit le service redis utilisant l’image de même nom du
Docker Hub qui sera accessible par
le programme en test sous le nom redis (il est aussi possible de
définir des
alias) :
test: stage: test services: - redis:6.2.5-alpine script: - cd go/src - go test -race -p 1 ./...
Mise au point de la CI¶
Il peut être difficile et un peu laborieux de mettre au point un fichier
.gitlab-ci.yml : on modifie, on commit, on pousse, on voit qu’il y a
des erreurs et on recommence. Trois outils nous permettent d’être plus
efficace :
l’outil CILint disponible sur la page Pipelines votre projet. Vous pouvez y coller votre configuration et les erreurs de syntaxe ou de configuration seront signalées.
-
le lancement en local d’un job d’intégration continue via l’outil
gitlab-runner:Installer
gitlab-runnersur votre poste (voir les instructions),-
Lancer le job
testspar la commandegitlab-runner exec docker tests. Le paramètredockersignifie que le job sera lancé dans une image docker (ce qui nécessite d’avoir un démon ou service docker activé). On peut utiliser le paramètreshellà la place dedockersi le job n’a pas besoin d’environnement spécifique pour s’exécuter.Cette utilisation reste limitée à des jobs simples (par exemple, la directive extends ne semble pas prise en compte et il n’est pas possible de dérouler tout un pipeline).
Utiliser l’outil tiers gitlab-ci-local qui devrait permettre de dérouler tout un pipeline en local. Je l’ai utilisé avec plus ou moins de succès en fonction de la complexité des jobs.
Note
Si vous avez des remarques ou questions à propos de cet article, n’hésitez pas à me contacter ou à ouvrir un ticket ou une merge request sur le projet gitlab du blog.
- 1
-
si vous avez besoin de mettre en place un miroir de dépôt de PCB vers le gitlab, faites une demande au SI.
- 2
-
un runner est un service qui est lancé sur une machine et qui communique avec l’instance gitlab pour savoir quels sont les jobs qui lui sont affectés.
À l’heure de l’écriture de cet article, un runner partagé est configuré sur la machine marouette (6 cpus i5-8500@3Ghz et 32 Go de RAM) dont vous pouvez visualiser l’occupation sur ce tableau de bord grafana.